PostgreSQL教程(十五):系统表详解
一、pg_class:该系统表记录了数据表、索引(仍然需要参阅pg_index)、序列、视图、复合类型和一些特殊关系类型的元数据。注意:不是所有字段对所有对象类型都有意义。 名字类型引用描述relnamename 数据类型名字。relnamespaceoidpg_namespace.oid包含这个对
一、pg_class:该系统表记录了数据表、索引(仍然需要参阅pg_index)、序列、视图、复合类型和一些特殊关系类型的元数据。注意:不是所有字段对所有对象类型都有意义。 名字类型引用描述relnamename 数据类型名字。relnamespaceoidpg_namespace.oid包含这个对
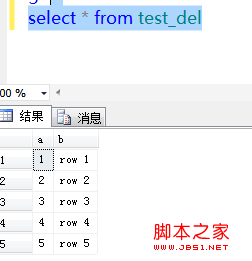
首先,我需要强调下,这篇主旨是揭示堆表的删除记录找回的原理,我所考虑的方面并不适用于每个人的每种情况,望大家见谅~ 很多朋友认为数据库在简单模式下,堆表误删除一条记录,是无法找回的,因为没有日志记录。其实不然,某种意义上是可以找回的,因为堆表在删除记录时,只更改了行偏移,实际数据没有被物理删除,所以
在设计主键的时候往往需要考虑以下几点: 1.无意义性:此处无意义是从用户的角度来定义的。这种无意义在一定程度上也会减少数据库的信息冗余。常常有人称呼主键为内部标识,为什么会这样称呼,原因之一在于“内部”,所谓内部从某种程度上来说就是指表记录,从大的范围来说就是数据库,如果你在设计的时候选择了对用户来
实现代码如下: CREATE TABLE #tmptb(tbname sysname,tbrows int ,tbREserved varchar(10),tbData varchar(10) ,tbIndexSize varchar(10),tbUnUsed varchar(10)) INSERT
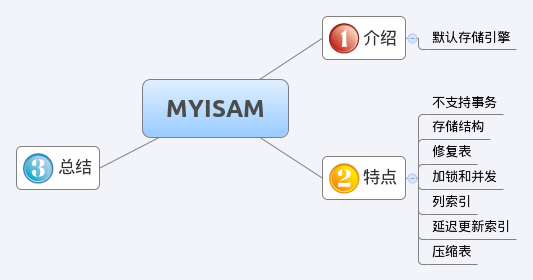
思维导图介绍mysql中用的最多存储引擎就是innodb和myisam。做为Mysql的默认存储引擎,myisam值得我们学习一下,以下是我对《高性能MYSQL》书中提到的myisam的理解,请大家多多指教。特点 > 不支持事务证明如下:>> 表记录:t2表的engine是myis
在MySQL中,使用auto_increment类型的id字段作为表的主键,并用它作为其他表的外键,形成“主从表结构”,这是数据库设计中常见的用法。但是在具体生成id的时候,我们的操作顺序一般是:先在主表中插入记录,然后获得自动生成的id,以它为基础插入从表的记录。这里面有个困难,就是插入主表记录后
但是用IN的SQL性能总是比较低的,从SQL执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别: SQL试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询。由此可见用IN的SQL至少多了一个转换的过程。一般的SQ
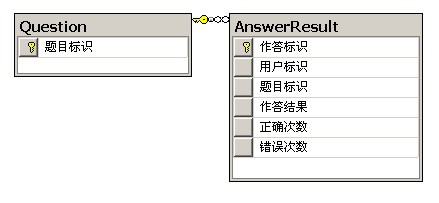
先简单介绍一下项目背景。这是一个在线考试练习平台,数据库使用MySQL,表结构如图所示:Question是存储题目的表,数据量在3万左右。AnswerResult表是存储用户作答结果的表,分表之后单表记录大概在300万-400万。需求:根据用户的作答结果出练习卷,题目的优先级为:未做过的题目>
1.搜索出所有表名,构造为一条SQL语句 实现代码如下: declare @trun_name varchar(8000) set @trun_name='' select @trun_name=@trun_name + 'truncate table ' + [name] + ' ' from s
但是如何得到某个数据库所有的表的记录数,你要是用上面的方法估计得累死了。呵呵 下面提供如何借用sysindexes和sysobjects表来得到某个数据库每个表记录数的方法: 先给出SQL Server 2000版本的: 实现代码如下: SELECT o.NAME, i.rowcnt FROM sy