正则表达式学习问答
举个简单的例子吧,Unix下的usr、dev等名字,就是那时留传下来的,现在已经有很多人诟病了,usr不是user,dev不是device,难学,也难记。经过这些年的飞速发展,当年的很多问题已经被包装得美轮美奂,如今的用户可能更习惯直接点击“用户目录”、“驱动器”之类的图标,再也不用为那些不规则的简
举个简单的例子吧,Unix下的usr、dev等名字,就是那时留传下来的,现在已经有很多人诟病了,usr不是user,dev不是device,难学,也难记。经过这些年的飞速发展,当年的很多问题已经被包装得美轮美奂,如今的用户可能更习惯直接点击“用户目录”、“驱动器”之类的图标,再也不用为那些不规则的简
思路 使用正则式 "(?x) (?: [\w-]+ | [\x80-\xff]{3} )"获得utf-8文档中的英文单词和汉字的列表。 使用dictionary来记录每个单词/汉字出现的频率,如果出现过则+1,如果没出现则置1。 将dictionary按照value排序,输出。 源码 实现代码如下:
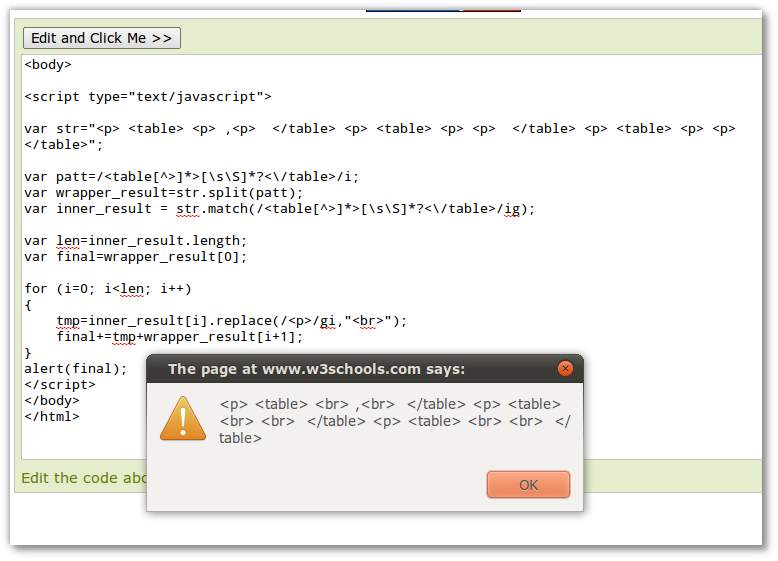
网友wys提问:如何仅使用JavaScript支持的正则语法,将 实现代码如下: 中...之间的都替换为? 思考 该问题的难点之一在于JavaScript支持的正则特性实在有限。楼主已经想到了非JavaScript的解法,如下: 实现代码如下: re=/(?)(?=.*?)/gi;
实现代码如下: public static void main(String[] args) { String sql = "SELECT * FROM \n" + " `testdb`.`foo` LIMIT 0, 100"; String s = "SELECT * FROM `testdb`.
从Java1.4起,Java核心API就引入了java.util.regex程序包,它是一种有价值的基础工具,可以用于很多类型的文本处理, 如匹配,搜索,提取和分析结构化内容.java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。它包括两个类:Pattern和M
先看要解析的样例SQL语句: 实现代码如下: select * from dual SELECT * frOm dual Select C1,c2 From tb select c1,c2 from tb select count(*) from t1 select c1,c2,c3 from t1
实现代码如下: Function closeHTML(strContent) Dim arrTags, i, OpenPos, ClosePos, re, strMatchs, j, Match Set re = New RegExp re.IgnoreCase = True re.Global =
简单解释一些代码: 第一个 ~(]+?>)~si 这个正则是匹配中的内容。简单说是所有的。 第二个 ~]*?/>~si 这个正则是匹配中的内容。是单闭合标签 如 第三个 ~]*?>~si 这个正则是匹配中的内容。也就是结束标签 如 第四个 ~]*?>~si 匹配中的内容。这和
对于有重复的5到10位数字可以使用\d{5,10} 这样的正则 无重复的5到10位数字我考虑了一下还不会,最然只好查网上。 有一个版本还不错,反正RegexBuddy测试通过了。 实现代码如下:^(?!\d*?(\d)\d*?\1)\d{5,10}$对于(?!………(……)………\1)这样的形式我还

我使用DW 这个所见所得的编辑器来写html时,喜欢写上注释,如 等等的注释,在一次比较大的改动时,需要批量查找替换,为了批量操作,于是我写了一个正则表达式来进行处理。 查找: 实现代码如下: (\r\n|\n|.)*?效果如图: 还有一个常用的就是字符串之间的字符 如:查找 到之间的字符,包括换行