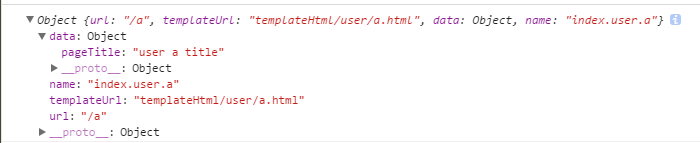
Angular设置title信息解决SEO方面存在问题
Javascript框架在处理seo方面存在问题,因为爬虫在检索seo信息的时候会读不了js给其赋的值,导致搜索引擎收录不了或者收录了无效的信息,比如收录的可能是title={{title}}这样的,下面先说如何在路由跳转时修改页面的seo信息,现在spa跳转一般用route-ui了,就以这个为基础
Javascript框架在处理seo方面存在问题,因为爬虫在检索seo信息的时候会读不了js给其赋的值,导致搜索引擎收录不了或者收录了无效的信息,比如收录的可能是title={{title}}这样的,下面先说如何在路由跳转时修改页面的seo信息,现在spa跳转一般用route-ui了,就以这个为基础
相信很多站长遇到过这种情况:网站内的搜索功能被不良分子利用,通过在站内搜索框中不断搜索敏感关键词,产生一大批TITLE上带有敏感关键词的垃圾搜索结果页(如下图)。由于Baiduspider对每个站点的抓取额是有限定的,所以这些垃圾搜索结果页被百度收录,会导致其它有意义的页面因配额问题不被收录,同时可
最近发现知道和问问小偷的版本越来越多了!! 看过一个百度小偷的网站也达到了pr6。收录十万多!! 在经过 荐礼啦 四十天的实践之后 发现百度对这个确实挺友好的。 从网站访问来看 很多也是从百度搜索来的! 所以用知道和问问来填充网站内容还是可行的。 于是自己开发了一个知道 问问的采集插件 原则上适合
最近大家在访问的时候,无法打开页面,经和机房人员的多次交流,发展原来是 机房的一个机器中了arp病毒,听机房说做了端口隔离(就是内网的机器无法互相访问),也许我们的网段比较特殊,在这个端口隔离之外了,唉。最终解决了这个问题,感谢大家对我们的支持。另:庆祝下百度终于继续收录了我们的网站。
关于页面优化和伪静态 1)版面优化 2)伪静态(重点涉及apache,smarty,正则) 详细内容: 一、版面优化: 版面优化其实主要涉及HTML,JS,CSS,XML之间的关系(XML相关在此不作描述). 1)一般来说,在资源共享的前提下,我们最基本的目的是让搜索引擎所收录(很多人被AJAX所迷
1、静态网页与动态比较: 1)静态网页: 优势:A、 对搜索引擎友好,被收录的质量高;B、访问速度快;C、资源(cpu 等)占用少。 劣势:A、对于大型门户,或者社区来说,不断的修改将会产生大量I/O,会导致磁盘出现碎片甚至出现磁盘坏道。相当恐怖一个隐患。用户信息一旦没有了就没戏玩了。B、储存空间占
很多空间商为了防止攻击,打开了硬防火墙,虽然临时解决了攻击问题,但是大大影响了百度和GOOGLE收录, 本人的一个小空间就因为地址被加上了?jdfwkey=jkd3k这样的后缀被大片大片的砍掉收录,最后,连搜索都没有登记了. 非常之郁闷啊. 有什么办法解决吗?有,一是换空间,二是让空间商关闭硬防.非
1.关于伪静态的用处 有些用户觉得,伪静态和真静态实际被收录量会相差非常大,其实不然,从你个人角度,你去判断一下一个帖子到底是真静态还是伪静态?估计非常难看得出,因为所谓静态的意思,就是地址中不带问号,不带问号的就是静态,管他是真的还是伪的?搜索引擎看得出吗?所以说,其实不论是真的还是伪的,其实对于
当然百度的流量大家也是知道的。相信做的网站的朋友都知道。你的站一旦百度收到好词,流量就一发不可收拾。大家都喜欢这样。可是好词谁都想要。但网站又不是你一个人有。大家都有。如何做到让百度上你的词排名靠前呢。下面简单的说一下:(适合新手篇),老江湖莫扔馒头来砸。。。。。1.新注册域名,开始后,放上网站程序
让站长最头痛的事,除了程序和服务器安全外,可能就要算内容被采集了。当然,现在网络本身就是资源共享,我这里不谈采集的对错,只是就防采集说说个人看法。一、如何分辨搜索爬虫以前,在网上看到过关于用asp代码来捕捉搜索爬虫的代码,通过代码把爬虫的访问记录记录到文件。就此代码(原作者未知)我作了修改,加入程序