
c# 抓取Web网页数据分析
为了完成以上的需求,我们就需要模拟浏览器浏览网页,得到页面的数据在进行分析,最后把分析的结构,即整理好的数据写入数据库。那么我们的思路就是: 1、发送HttpRequest请求。 2、接收HttpResponse返回的结果。得到特定页面的html源文件。 3、取出包含数据的那一部分源码。
为了完成以上的需求,我们就需要模拟浏览器浏览网页,得到页面的数据在进行分析,最后把分析的结构,即整理好的数据写入数据库。那么我们的思路就是: 1、发送HttpRequest请求。 2、接收HttpResponse返回的结果。得到特定页面的html源文件。 3、取出包含数据的那一部分源码。

本文实例讲述了python Scrapy框架第一个入门程序。分享给大家供大家参考,具体如下:首先创建项目:scrappy start project maitian第二步: 明确要抓取的字段items.pyimport scrapyclass MaitianItem(scrapy.Item):# d

我们先来看一下运行图下面我们来看源代码:data)-1;$getInfos=@json_decode(json_decode($content)->data[$c]->content)->sub_raw_datas;if ($getInfos){foreach ($getInfos
相信很多站长遇到过这种情况:网站内的搜索功能被不良分子利用,通过在站内搜索框中不断搜索敏感关键词,产生一大批TITLE上带有敏感关键词的垃圾搜索结果页(如下图)。由于Baiduspider对每个站点的抓取额是有限定的,所以这些垃圾搜索结果页被百度收录,会导致其它有意义的页面因配额问题不被收录,同时可
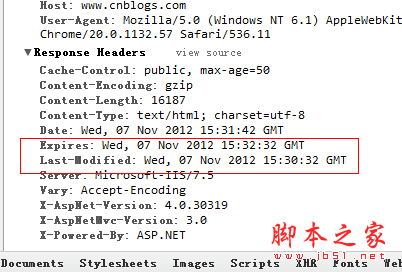
一:网页更新 我们知道,一般网页中的信息是不断翻新的,这也要求我们定期的去抓这些新信息,但是这个“定期”该怎么理解,也就是多长时间需要抓一次该页面,其实这个定期也就是页面缓存时间,在页面的缓存时间内我们再次抓取该网页是没有必要的,反而给人家服务器造成压力。 就比如说我要抓取博客园首页,首先清空页面缓
之前还以为从上至下统一用上UTF-8就高枕无忧了,哪知道今天在抓取新浪微博的数据的时候还是遇到字符的异常。 从新浪微博抓到的数据在入库的时候抛出异常: Incorrect string value: '\xF0\x90\x8D\x83\xF0\x90...' 发现导致异常的字符不是繁体而是某种佛经文
内网用户或代理上网的用户使用 实现代码如下: using System.IO; using System.Net; public string get_html() { string urlStr = "http://www.domain.com"; //設定要獲取的地址 HttpWebReques
URL 静态化可以提高搜索引擎抓取,开启本功能需要对 Web 服务器增加相应的 Rewrite 规则,且会轻微增加服务器负担。本教程讲解如何在 IIS 环境下配置各个产品的 Rewrite 规则。一、首先下载 Rewrite.zip 的包,解压到任意盘上的任意目录。各个产品的 Rewrite 规则包

Web 前端代码实现代码如下: 标题 发布作者 发布时间 ' target="_blank"> ' target="_blank"> cs 后台代码: 实现代码如下: using System; using
实现代码如下: /** * CURL请求 * @param String $url 请求地址 * @param Array $data 请求数据 */ function curlRequest($url,$data='',$cookieFile=''){ $ch = curl_init(); $op