javascript对数组的常用操作代码 数组方法总汇
1. shift:删除原数组第一项,并返回删除元素的值;如果数组为空则返回undefined var a = [1,2,3,4,5]; var b = a.shift(); //a:[2,3,4,5] b:1 2. unshift:将参数添加到原数组开头,并返回数组的长度 var a = [1,2,
1. shift:删除原数组第一项,并返回删除元素的值;如果数组为空则返回undefined var a = [1,2,3,4,5]; var b = a.shift(); //a:[2,3,4,5] b:1 2. unshift:将参数添加到原数组开头,并返回数组的长度 var a = [1,2,
问题:短信息审核的时候,会根据内容来进行判断,比如a内容可以通过,b内容不能通过,则MySQL中表现为 msg = a,msg = b,可是如果msg字段的内容中包含回车换行等空白字符(最常见的是内容开头和末尾出现换行),则比对就不成功,造成短信息审核不成功。 由于内容插入的时候没办法进行完全的过滤

常用到的元字符有: . 查找单个字符,除了换行和行结束符; \w 匹配字母、汉字、数字、下划线等符号; \s 匹配空白符(包含空格、制表符等); \d 匹配数字; \b 匹配位于单词的开头或结尾的匹配; 常用的量词有: ^n 匹配任何开头为 n 的字符串; n$ 匹配任何结尾为 n 的字符串; n+
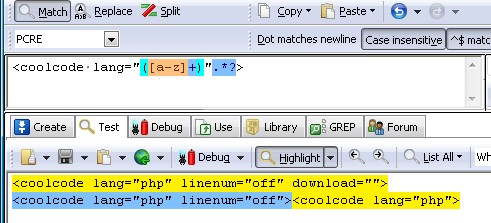
最近,我抽空改成SyntaxHighlighter。由于coolcode插件的开头标签是 或者[coolcode]这样的,而SyntaxHighlighter是 [code lang="php"] 这样的(或者其他)。遂只能想办法把老的格式转化成新的格式。当然,肯定用到正则表达式了。 原来的代码高
先来说说实现方式: 1、我们来假定Table中有一个已经建立了索引的主键字段ID(整数型),我们将按照这个字段来取数据进行分页。 2、页的大小我们放在@PageSize中 3、当前页号我们放在@CurrentPage中 4、如何让记录指针快速滚动到我们要取的数据开头的那一行呢,这是关键所在!有了Se
语法规则如下: $('a[href$="ABC"]')... 支持的选择方式如下: = 判断完全相符; != 不相符; ^=以某字符串开头; $=以某字符串结尾; *=包含某字符串。 进一步,可以通过$('a[href$="ABC"]:first')返回结果集中的第一条记录 如果需要遍历结果集: 实
1、'UTF转GB---将UTF8编码文字转换为GB编码文字 实现代码如下: function UTF2GB(UTFStr) for Dig=1 to len(UTFStr) '如果UTF8编码文字以%开头则进行转换 if mid(UTFStr,Dig,1)="%" then 'UTF8编码文字大于
那么就让sql server等一些非windows必要服务开机不启动,等用的时候再用批处理启动即可: 首先将“控制面板->管理工具->服务”里面的SQL SERVER相关的服务启动类型设置为手动(SQL Server开头的服务),然后新建立一个文本文档,把后缀名改为“bat”。下面就添加
1.日期属性列,不会因为有分秒差别而减慢查询速度 2. 使用LIKE比较进行查询时,如果模式以特定字符串如“abc%”开头,使用索引则会提高效率;如果模式以通配符如“%xyz”开头,则索引不起作用 3. OR会引起全表扫描,且和IN的作用相当 4. 尽量少用NOT 5. EXISTS 和 IN的执行
关于“回溯”我也是第一次接触,对它也不算很了解。下面就把我所了解的做为一个心德记录下来,以备查看。 我们所使用的正则表达式的匹配基础大概分为:优先选择最左端(最靠开头)的匹配结果和标准的匹配量词(*、+、?和{m, n})是匹配优先的。 “优先选择最左端的匹配”顾名思义就是从字符串的起始位置开始匹配