C#自动获取文件编码txt自动判断文件编码
今天在用c#读取txt文件,乱码了,用默认的编码不行,得用指定的编码才可以.因为每个文件的编码可能都不一样,有没有一种一劳永逸的方法,那肯定是有~自动判断文件的编码.下面就直接上代码了.public static Encoding GetEncoding(string filename){try{r
今天在用c#读取txt文件,乱码了,用默认的编码不行,得用指定的编码才可以.因为每个文件的编码可能都不一样,有没有一种一劳永逸的方法,那肯定是有~自动判断文件的编码.下面就直接上代码了.public static Encoding GetEncoding(string filename){try{r
基于令牌的处理就是一劳永逸的方法。 实现代码如下: function formsubmit() { Today = new Date(); var NowHour = Today.getHours(); var NowMinute = Today.getMinutes(); var NowSeco
可谓一劳永逸,不要重复造轮子:) 1.常用的方法统一放置 例如:在用户注册时,时常需要判断文本框中字符是否是汉字、英文、数字或邮箱地址等等。何不把这些方法统一放在一个脚本中,取名叫做utility.js呢? 实现代码如下://待需要时另存为一个js function isNull(obj) { if
方法一:利用Cookies,一劳永逸 Cookies能通过IE的“文件-导入和导出”将登录信息通过Cookies导出保存(傲游这个功能MS不能用),曾见过有人撰文说将“FALSE”空格后面的“10********”修改为“16********”可以将有效期增加至20年(在IE缓存中选择详细信息查看方
由于软件的增多,而不同软件所需的系统配置并不相同,致使我们需要经常改变配置,如果每次都改写config.sys是相当麻烦的,于是DOS设计了菜单式多重任务选择的配置,就方便多了,比如有些游戏无需扩展内存,有些又必须有扩展内存,有些汉字系统还必须设置虚拟盘等,采用多重设置将是一劳永逸的事。 例:两种
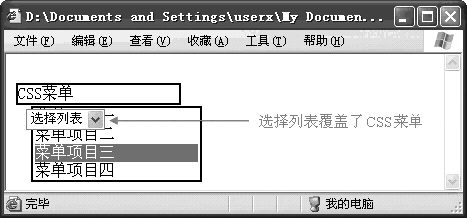
在设计HTML页面的过程中经常会遇到表单元素覆盖样式元素引起的问题,图一就是一个典型的例子。不要小看这个貌似“低级”的问题,即使一些规模较大的网站上类似的问题也绝不鲜见。本文探讨了造成这一问题的根本原因,并提出一种补救办法——之所以说补救办法而不是一劳永逸的解决办法,是因为微软和NetScape这两