
深入sql oracle递归查询
☆ 获取数据库所有表名,表的所有列名select name from sysobjects where xtype='u'select name from syscolumns where id=(select max(id) from sysobjects where xtype='u' and
☆ 获取数据库所有表名,表的所有列名select name from sysobjects where xtype='u'select name from syscolumns where id=(select max(id) from sysobjects where xtype='u' and
row_number()over(partition by col1 order by col2)表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。 与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪劣row
表可以按range、hash、list分区,表分区后,其上的索引和普通表上的索引有所不同,oracle对于分区表上的索引分为2类,即局部索引和全局索引,下面分别对这2种索引的特点和局限性做个总结。局部索引local index1.局部索引一定是分区索引,分区键等同于表的分区键,分区数等同于表的分区数

方法一 实现代码如下: declare @max integer,@id integer declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) > 1 open cu
一. 删除完全重复的记录完全重复的数据,通常是由于没有设置主键/唯一键约束导致的。测试数据:实现代码如下:if OBJECT_ID('duplicate_all') is not nulldrop table duplicate_all GO create table duplicate_all (
在程序中定义变量、常量和参数时,则必须要为它们指定PL/SQL数据类型。在编写PL/SQL程序时,可以使用标量(Scalar)类型、复合(Composite)类型、参照(Reference)类型和LOB(LargeObject)类型等四种类型。在PL/SQL中用的最多的就是标量变量,当定义标量变量时
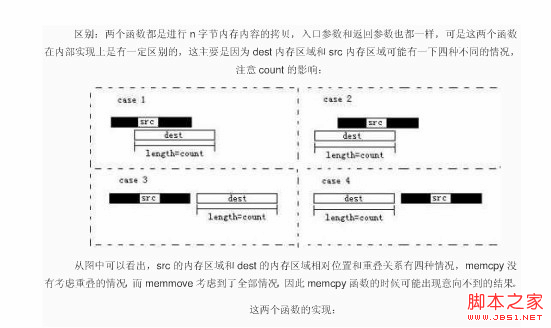
代码如下所示:实现代码如下:// MemMove.cpp : 定义控制台应用程序的入口点。//#include "stdafx.h"#include using namespace std;实现代码如下:void* memmove(void* dest, const void* src, size_

#include #include using namespace std; void main(){实现代码如下: ////find函数返回类型 size_typestring s("1a2b3c4d5e6f7g8h9i1a2b3c4d5e6f7g8ha9i");string flag;strin
函数itoa()是将整数型转换为c语言风格字符串的函数,原型:char * itoa(int data, char*p, int num);data是传入的带转化的数字,为整型变量(data的最大值为2的31次方减去1),p是传入的字符型指针,指向存储转换后字符串空间的首地址;num指定要转换成几进
可以使用atexit()函数注册一个函数,代码如下:实现代码如下:#include "stdafx.h"#include using namespace std;//int _onexit(void (*function)(void)); //这句可以要也可以不要void f1(){ cout &l