浅谈内联函数与宏定义的区别详解
用内联取代宏:1.内联函数在运行时可调试,而宏定义不可以;2.编译器会对内联函数的参数类型做安全检查或自动类型转换(同普通函数),而宏定义则不会; 3.内联函数可以访问类的成员变量,宏定义则不能; 4.在类中声明同时定义的成员函数,自动转化为内联函数。文章(一)内联函数与宏定义 在C中,常用预处理
用内联取代宏:1.内联函数在运行时可调试,而宏定义不可以;2.编译器会对内联函数的参数类型做安全检查或自动类型转换(同普通函数),而宏定义则不会; 3.内联函数可以访问类的成员变量,宏定义则不能; 4.在类中声明同时定义的成员函数,自动转化为内联函数。文章(一)内联函数与宏定义 在C中,常用预处理
“清除系统垃圾.bat”,“clear.bat”,“一键清除系统垃圾.bat”,“30秒清除系统垃圾.bat”,“快速清除系统垃圾.bat” 基本上找到的者是一个文件, 但这里面也有很多不足或需要改进的地方,但大多数人看不懂DOS命令,所以被改的机会会很少,下面是我所发现的问题及其改进,可以说是比较

一.C语言中的static关键字在C语言中,static可以用来修饰局部变量,全局变量以及函数。在不同的情况下static的作用不尽相同。(1)修饰局部变量一般情况下,对于局部变量是存放在栈区的,并且局部变量的生命周期在该语句块执行结束时便结束了。但是如果用static进行修饰的话,该变量便存放在静
(一)非递归全排列算法基本思想是:1.找到所有排列中最小的一个排列P.2.找到刚刚好比P大比其它都小的排列Q,3.循环执行第二步,直到找到一个最大的排列,算法结束.下面用数学的方法描述:给定已知序列 P =A1A2A3An ( Ai!=Aj , (1 P(i-1) (1 P(i+2) > .
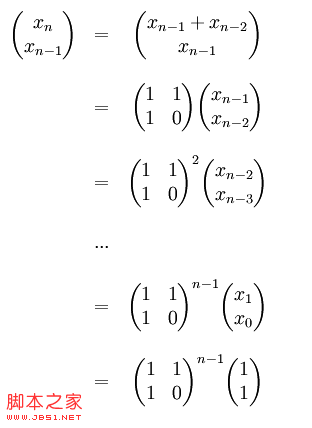
一:递归实现使用公式f[n]=f[n-1]+f[n-2],依次递归计算,递归结束条件是f[1]=1,f[2]=1。二:数组实现空间复杂度和时间复杂度都是0(n),效率一般,比递归来得快。三:vector实现时间复杂度是0(n),时间复杂度是0(1),就是不知道vector的效率高不高,当然vecto
阶乘(Factorial)是个很有意思的函数,但是不少人都比较怕它,我们来看看两个与阶乘相关的问题: 1、 给定一个整数N,那么N的阶乘N!末尾有多少个0呢?例如:N=10,N!=3 628 800,N!的末尾有两个0。2、求N!的二进制表示中最低位1的位置。 有些人碰到这样的题目会想:是不是要完整
题目:输入一个整形数组,数组里有正数也有负数。数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和。求所有子数组的和的最大值。要求时间复杂度为O(n)。 例如输入的数组为1, -2, 3, 10, -4, 7, 2, -5,和最大的子数组为3, 10, -4, 7, 2,因此输出为该子数组
前言:最近在学习《Unix编程艺术》。以前粗略的翻过,以为是介绍unix工具的。现在认真的看了下,原来是介绍设计原则的。它的核心就是第一章介绍的unix的哲学以及17个设计原则,而后面的内容就是围绕它来展开的。以前说过,要学习适合自己的资料,而判断是否适合的一个方法就是看你是否能够读得下去。我对这本
《代码大全》建议在变量定义的时候进行初始化,但是很多人,特别是新人对结构体或者结构体数组定义是一般不会初始化,或者不知道怎么初始化。1、初始化实现代码如下:typedef struct _TEST_T {int i;char c[10];}TEST_T;TEST_T gst= {1, “12345”
我们都知道Dictionary查找元素非常快,其实现原理是:将你TKey的值散列到数组的指定位置,将TValue的值存入对应的位置,由于取和存用的是同一个算法,所以就很容易定位到TValue的位置,花费的时间基本上就是实现散列算法的时间,跟其中元素的个数没有关系,故取值的时间复杂度为O(1)。集合无