
mysql 海量数据的存储和访问解决方案
第1章引言随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。水平切分数据库,可以降低单台
第1章引言随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。水平切分数据库,可以降低单台

这里的分表逻辑是根据t_group表的user_name组的个数来分的。因为这种情况单独user_name字段上的索引就属于烂索引。起不了啥名明显的效果。1、试验PROCEDURE.DELIMITER $$DROP PROCEDURE `t_girl`.`sp_split_table`$$CREAT
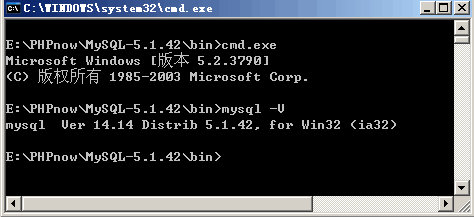
第一种方法:1:在终端或windows下:mysql -V 即可。能看出来版本是mysql Ver 14.14 Distrib 5.1.42, for Win32 (ia32),这个里面的5.1.42就是版本了。第二种:在mysql中:mysql> status; 这个需要登录以后才可以。my
desc 表名; show columns from 表名; describe 表名; show create table 表名; use information_schema select * from columns where table_name='表名'; 顺便记下: show datab
show tables或show tables from database_name; // 显示当前数据库中所有表的名称 show databases; // 显示mysql中所有数据库的名称 show columns from table_name from database_name; 或sh
SELECT语句,去除某个字段的重复信息,例如: 表名:table id uid username message dateline 1 6 a 111 1284240714(时间戳) 2 6 a 222 1268840565 3 8 b 444 12667
Mysql数据库备份的常用3种方法: 1、直接拷贝(cp、tar,gzip,cpio) 2、mysqldump 3、mysqlhotcopy 1.使用直接拷贝数据库备份 典型的如cp、tar或cpio实用程序。 当你使用直接备份方法时,必须保证表不在被使用。如果服务器在你正在拷贝一个表时改变它,拷贝
数据库: 30万条,有ID列但无主键,在要搜索的“分类”字段上建有非聚集索引 过程T-SQL: 实现代码如下: /* 用户自定义函数:执行时间在1150-1200毫秒左右 CREATE FUNCTION [dbo].[gethl] (@types nvarchar(4)) RETURNS table
INSERT语法 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [(col_name,...)] VALUES ({expr | DEFAULT},...),(...),... [ ON DUPLIC
实现代码如下:INSERT table (auto_id, auto_name) values (1, ‘yourname') ON DUPLICATE KEY UPDATE auto_name='yourname'ON DUPLICATE KEY UPDATE的使用 如果您指定了ON DUPLIC