
基于大端法、小端法以及网络字节序的深入理解
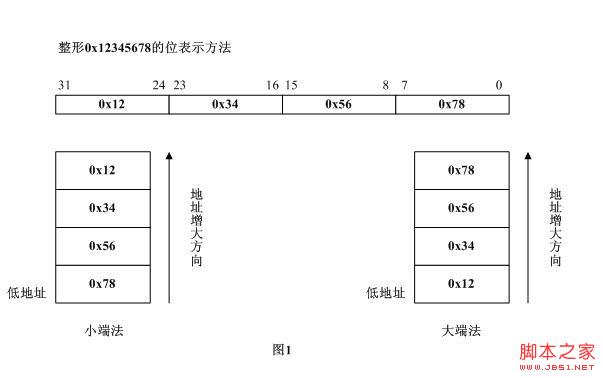
关于字节序(大端法、小端法)的定义《UNXI网络编程》定义:术语“小端”和“大端”表示多字节值的哪一端(小端或大端)存储在该值的起始地址。小端存在起始地址,即是小端字节序;大端存在起始地址,即是大端字节序。 也可以说: 1.小端法(Little-Endian)就是低位字节排放在内存的低地址端即该值的
关于字节序(大端法、小端法)的定义《UNXI网络编程》定义:术语“小端”和“大端”表示多字节值的哪一端(小端或大端)存储在该值的起始地址。小端存在起始地址,即是小端字节序;大端存在起始地址,即是大端字节序。 也可以说: 1.小端法(Little-Endian)就是低位字节排放在内存的低地址端即该值的

个人做了一些自定义的修改 实现代码如下: jQuery(function($){ var el; $("select").each(function() { el = $(this); el.data("origWidth", el.css("width")); // el.data("oriW

erase的作用是,使作为参数的迭代器失效,并返回指向该迭代器下一参数的迭代器。如下:实现代码如下:list ParticleSystem;list::iterator pointer;if(pointer->dead == true){pointer = ParticleSystem.era
在做校园网视频网站的时候,首页有一个导航页面要实现滚动效果,有样例,但代码是在难弄懂,貌似网页设计这块还是只有自己的代码自己懂,索性就仿造别人的效果自己做了一个,大体上还行,看起来还是比较流畅的,不次于原作的幺。 现在先把代码拷贝到这里,以后再逐一简化修改: 实现滚动效果,脚本代码如下: 实现代码如
今天用ftruncate截断文件, 但怎么都不能达到预料的效果, 截断后文件中的内容比较杂, 而且文件大小也保持原来的.添加 fflush() 和 rewind() 后OK.以下是测试代码:实现代码如下:#include #include #include int main(){ FILE *fp;
fflush用于清空缓冲流,虽然一般感觉不到,但是默认printf是缓冲输出的。 fflush(stdout),使stdout清空,就会立刻输出所有在缓冲区的内容。 fflush(stdout)这个例子可能不太明显,但对stdin很明显。 如下语句: int a,c; scanf("%d", c=g
前言 对于jQuery的数据缓存,相信大家都不会陌生,jQuery缓存系统不仅运用于DOM元素,动画、事件等都有用到这个缓存系统。所以在平时实际应用中, 我们经常需要给元素缓存一些数据,并且这些数据往往和DOM元素紧密相关。由于DOM元素(节点)也是对象, 所以我们可以直接扩展DOM元素的属性,但是
select * fromtablewherenumber like '%/%%' escape '/'...sqlite3数据库在搜索的时候,一些特殊的字符需要进行转义, 具体的转义如下:/->//'->''[->/[]->/]%->/%keyWord = keyWo
我们针对常用的jQuery方法以及其等价原生方法的性能做了一些测试(1, 2, 3)。 我知道你在想什么。原生方法明显要比jQuery方法快,因为jQuery方法要处理浏览器兼容以及其他一些事情。是的,我完全赞成。写这篇文章并不是出于反对使用jQuery,但如果你针对的是现代浏览器,那么使用原生方法
先看下面一个例子a.c :实现代码如下:int main(int argc, char *argv[]){ fprintf(stdout, "normal\n"); fprintf(stderr, "bad\n"); return 0;}$ ./anormalbad$ ./a > tmp 2&