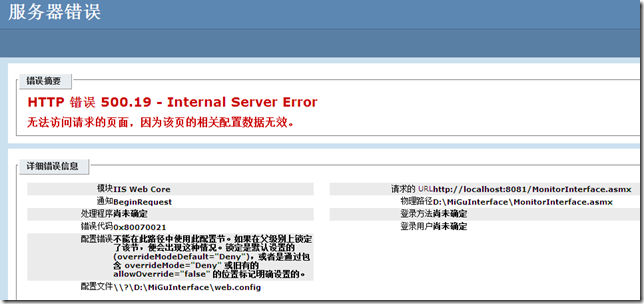
HTTP 错误 500.19- Internal Server Error 错误解决方法
刚在本机部署了一个WebService测试,浏览的时候出现了“HTTP 错误 500.19 - Internal Server Error ”错误,如下图:经过检查发现是由于先安装vs2008后安装iis的缘故,只需重新注册下AspNet就可以了,具体步骤如下1 打开运行,输入cmd进入到命令提示符
刚在本机部署了一个WebService测试,浏览的时候出现了“HTTP 错误 500.19 - Internal Server Error ”错误,如下图:经过检查发现是由于先安装vs2008后安装iis的缘故,只需重新注册下AspNet就可以了,具体步骤如下1 打开运行,输入cmd进入到命令提示符
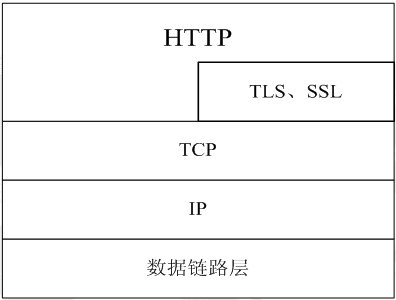
http协议学习系列1. 基础概念篇1.1 介绍HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task

对了,注意那个innerText和innerHTML 实现代码如下: function sortCells(event) { var obj = event.target; var count = 0; count是记录点击次数的,根据奇偶进行升序或降序 if(!obj.getAttribute("

开始 运行 services.msc单击 华众服务 右键 重新启动如果出现一直卡在启动对话框 没启动成功 或点重新启动出错 则需要重新加载服务,方法如下:1、打开任务管理器 关掉 有问题的华众进程 例:主控是hzhost.exe 右键结束进程2、假设装在D:/hzhost开始 运行 cmdd:cd
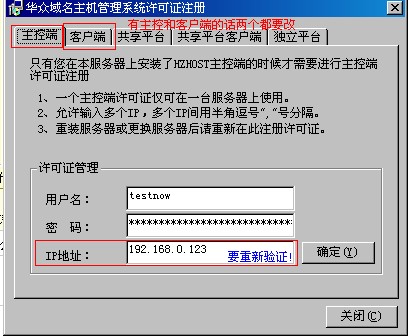
1.华众控制器—许可证注册,把旧的ip更改为新的ip,并确定通过验证,另外主控端和被控端参数设置里ip更改为新的;以下更改针对客户端2.更改hzhost主数据库里的ip->华众控制器->虚拟主机实用工具->IP更换工具->填写好主数据库信息(不知道密码的,可以在主站下查看X:
一:获取指定文件夹的文件 实现代码如下: procedure searchfile(path:string);//注意,path后面要有'\'; var SearchRec:TSearchRec; found:integer; begin found:=FindFirst(path+'*.*',fa

解决方法。在form中添加 novalidate 属性就可以解决这个问题,并且不影响在ie下的效果 例如: 详细解说见:http://www.w3.org/TR/html5/forms.html#attr-fs-novalidate
效果如下 原表格:col0col1col2col3SuZhou1111122222SuZhouCitySuZhou3333344444SuZhouCitySuZhou5555566666SuZhouCityShangHai7777788888ShangHaiCityShangHaiuuuuuhhhh
第一章:加载和执行 浏览器的JavaScript的引擎是编译器层的优化; 当浏览器执行JavaScript代码时,不能同时做其他任何事情(单一进程),意味着标签每次出现都霸道地让页面等带脚本的解析和执行(每个文件必须等到前一个文件下载并执行完成才会开始下载),所以头部的JS和CSS用来渲染页面,交互
1. jquery-mix.com2. jqueryfordesigners.com3. 15daysofjquery.com4. jqueryking.com5. addyosmani.com6. docs.jquery.com7. tutorialzine.com8. visualjquery.