关于Shell脚本效率优化的一些个人想法
一、先说一下Shell脚本语言自身的局限性 作为解释型的脚本语言,天生就有效率上边的缺陷。尽管它调用的其他命令可能效率上是不错的。 Shell脚本程序的执行是顺序执行,而非并行执行的。这很大程度上浪费了可能能利用上的系统资源。 Shell每执行一个命令就创建一个新的进程,如果脚本编写者没有这方面意识
一、先说一下Shell脚本语言自身的局限性 作为解释型的脚本语言,天生就有效率上边的缺陷。尽管它调用的其他命令可能效率上是不错的。 Shell脚本程序的执行是顺序执行,而非并行执行的。这很大程度上浪费了可能能利用上的系统资源。 Shell每执行一个命令就创建一个新的进程,如果脚本编写者没有这方面意识

先说一下最常见基本的系统瓶颈: 1、硬盘搜索。现代磁盘的平均时间通常小于10ms,因此理论上我们每秒能够大约搜索1000次,这样我们在这样一个磁盘上搜索一个数据,很难优化,一个办法就是将数据分布在多个磁盘。 2、IO读写。就磁盘来讲,一般传输10-20Mb/s,同样的,优化可以从多个磁盘并行读写。

php代码如下: 实现代码如下: array('request_fulluri'=>true)); $context = stream_context_create($opts); $content = file_get_contents($url,false,$context); //匹配i
1、根据身份证号码计算出生日期、年龄、性别(18位) 实现代码如下: //获取输入身份证号码 var UUserCard = $("#UUserCard").val(); //获取出生日期 //UUserCard.substring(6, 10) + "-" + UUserCard.substrin
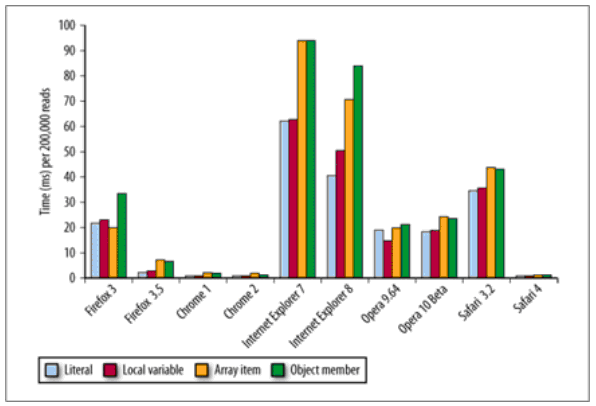
局部变量也就可以理解为在函数内部定义的变量,很明显访问局部变量要比域外的变量要快,因为它位于作用域链的第一个变量对象中(关于作用域链的介绍可以阅读这篇文章)。变量在作用域链的位置越深,访问所需要的时间就越长,全局变量总是最慢的,因为它们位于作用域链的最后一个变量对象。 每种数据类型的访问都需要付出点
一.WITH AS的含义 WITH AS短语,也叫做子查询部分(subquery factoring),可以让你做很多事情,定义一个SQL片断,该SQL片断会被整个SQL语句所用到。有的时候,是为了让SQL语句的可读性更高些,也有可能是在UNION ALL的不同部分,作为提供数据的部分。 特别对于U

后来在一个不起眼的小站找到一个帖子,某个人的一个建议提醒了我。 我原来的代码是这样写的: 错误代码 实现代码如下: $.ajax({ type: "post", url: "_service.asmx/getDataFromATable", data:" { tablename: temp }",
使用方法,新建一个.TXT文本文档,将以下红色区域代码粘贴进去。 然后保存成*.bat后缀或*.cmd后缀批处理文件格式即可运行使用! 1.关闭所有分区自动播放 实现代码如下: @ ECHO OFF @ ECHO. @ ECHO. 特 别 说 明 @ ECHO. @ ECHO -----------

我们先看一段传统的继承代码: 实现代码如下: //定义超类 function Father(){ this.name = "父亲"; } Father.prototype.theSuperValue = ["NO1","NO2"]; //定义子类 function Child(){ } //实现继承
最近在利用 SSRS 2005 做报表的时候,调用带有临时表的数据源时,系统会报错,并无法进入向导的下一步,错误如下: There is an error in the query. Invalid object name '#temptb'. 经过研究后想到如下三种解决方案: 1. 使用表变量代替