事实上还有很多特殊符号可用来分隔单个的命令:分号(;)、管道(|)、&、逻辑AND (&&),还有逻辑OR (||)。对于每一个读取的管道,Shell都回将命令分割,为管道设置I/O,并且对每一个命令依次执行下面的操作:
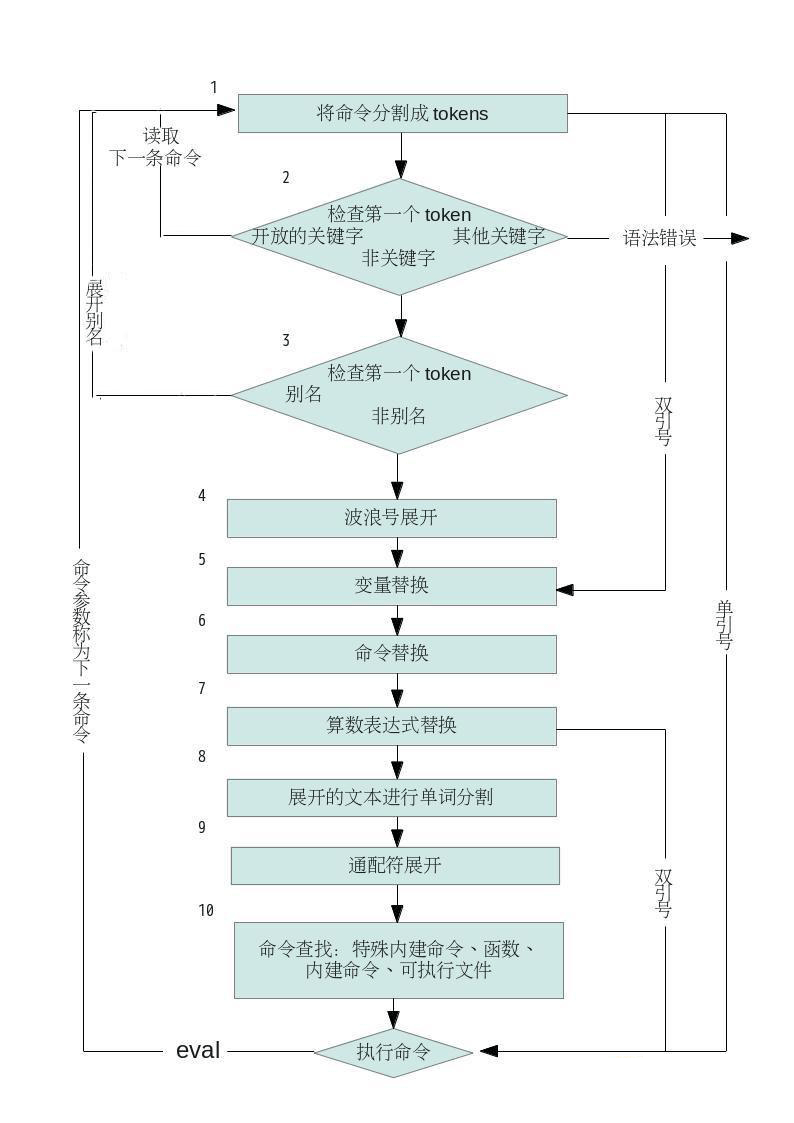
整个步骤顺序如上图所示,看起来有些复杂。当命令行被处理时,每一个步骤都是在Shell的内存里发生的;Shell不会真的把每个步骤的发生显示给你看。所以,你可以假想这事我们偷窥Shell内存里的情况,从而知道每个阶段的命令行是如何被转换的。我们从这个例子开始说:
实现代码如下:
$ mkidr /tmp/x 建立临时性目录
$ cd /tmp/x 切换到该目录
$ touch f1 f2 建立文件
$ f=f y="a b" 赋值两个变量
$ echo ~+/${f}[12] $y $(echo cmd subst )$ (( 3 + 2 )) > out 将结果重定向到out
上述的执行步骤概要如下:
1.命令一开始回根据Shell语法而分割为token。最重要的一点是:I/O重定向 >out 在这里是被识别的,并存储供稍后使用。流程继续处理下面这行,其中每个token的范围显示于命令下面的行上:
echo ~+/${f}[12] $y $(echo cmd subst) $((3 + 2))
| 1 | |----- 2 ----| |3 | |-------- 4----------| |----5-----|
2.检查第一个单词(echo)是否为关键字,例如 if 或 for 。这里不是,所以命令行不变继续处理。
3.检查第一个单词(echo)是否为别名。这里不是。所以命令行不变,继续处理。
4.扫描所以单词是否需要波浪号展开。在本例中,~+ 为ksh93 与 bash 的扩展,等同于$PWD,也就是当前的目录。token 2将被修改,处理如下:
echo /tmp/x/${f}[12] $y $(echo cmd subst) $((3 + 2))
| 1 | |------- 2 -------| |3 | |-------- 4----------| |----5-----|
5.下一步是变量展开:token 2 与 3 都被修改。这样会产生:
echo /tmp/x/${f}[12] a b $(echo cmd subst) $((3 + 2))
| 1 | |------- 2 -------| | 3 | |-------- 4----------| |----5-----|
6.再来要处理的是命令替换。注意,这里可用递归应用列表里的所有步骤!在这里,命令替换修改了 token 4:
echo /tmp/x/${f}[12] a b cmd subst $((3 + 2))
| 1 | |------- 2 -------| | 3 | |--- 4 ----| |----5-----|
7.现在执行算数替换。修改的是 token 5,结果:
echo /tmp/x/${f}[12] a b cmd subst 5
| 1 | |------- 2 -------| | 3 | |--- 4 ----| |5|
8.前面所有的展开产生的结果,都将再一次被扫描,看看是否有 $IFS 字符。如果有,则他们是作为分隔符(separator),产生额外的单词,例如,两个字符$y 原来是组成一个单词,单展开式“a- 空格-b”,在此阶段被切分为两个单词:a 与 b。相同方式也应用于命令$(echo cmd subst)的结果上。先前的 token 3 变成了 token 3 与
token 4.先前的 token 4则成了 token 5 与 token 6。结果:
echo /tmp/x/${f}[12] a b cmd subst 5
| 1 | |------- 2 -------| 3 4 |-5-| |- 6 -| 7
9.最后的替换阶段是通配符展开。token 2 变成了 token 2 与 token 3:
echo /tmp/x/$f1 /tmp/x/$f2 a b cmd subst 5
| 1 | |---- 2 ----| |---- 3 ----| 4 5 |-6-| |- 7 -| 8
10.这时,Shell已经准备好了要执行最后的命令了。它会去寻找 echo。正好 ksh93 与 bash 的 echo 都内建到Shell 中了。
11.Shell实际执行命令。首先执行 > out 的 I/O重定向,再调用内部的 echo 版本,显示最后的参数。
最后的结果:
实现代码如下:
$cat out
/tmp/x/f1 /tmp/x/f2 a b cmd subst 5
以上就是【Shell 命令执行顺序分析[图]】的全部内容了,欢迎留言评论进行交流!